1、概要介绍
1.1、数据库>时序数据库使用场景
所谓数据库>时序数据库就是按照一定规则的时间序列进行数据读写操作的数据库。它们常被用于以下业务场景:
- 物联网IOT场景:可用于IOT设备的指标、状态监控数据存取。
- IT建设场景:可用于服务器、虚拟机、容器的实时监控数据存取。
- 金融行业:各类金融产品及其衍生品、数字货币数据存储与量化研究。
- 各垂直领域:业务溯源、用户轨迹、状态日志。
有的读者可能就会问,这些场景不是普通的关系型数据库也可以适用吗?为什么需要更换结构化存储方案,而选择数据库>时序数据库呢?基本原因还是数据库>时序数据库针对特定业务场景的结构优势:
-
关于存储结构优势
数据库>时序数据库具有和关系型数据库不同的数据管理结构(后者一般基于B+树),目前主流的数据库>时序数据库基本采用LSM Tree(的变种),这种数据结构的主要思想是将一颗整树分解为存储在Disk的部分和存储在Memory的部分,并建立高效的数据交换算法。这有利于数据库>时序数据库对一段时间内需要高效读写的数据进行管理。
注意:这里的一个附加话题是,基本上数据库>时序数据库需要配合SSD磁盘甚至SSD存储阵列才能发挥其最佳I/O性能。所以,如果读者决定选用数据库>时序数据库,且附带的存储方案并不是诸如云厂商这样配套的存储方案,那么读者就要确保数据库>时序数据库配套的是SSD磁盘或者SSD存储阵列。
-
关于数据时效性
使用数据库>时序数据库的数据都有一定的数据时效性特点。例如,监控数据根据不同的监控场景,往往使用者最常查阅的就是72小时内的数据,超过72小时的数据虽然可能会在后续的数据分析中使用,但对于判断设备的实时状态就已经不再具备参考性了。另外条形码溯源场景中,只会对从条形码生成到条形码所对应的物品被使用完成这段时间内有时效性进行重点关注。一旦条形码对应的物品被使用完,这些溯源数据对于判定物品的实时状态就不再具有参考性了,只会在后续的数据统计、数据分析阶段再使用了。
InfluxDB__21">1.2、InfluxDB 介绍
InfluxDB就是一种数据库>时序数据库,除此之外目前业界流行的数据库>时序数据库还有Kdb、TDengine、Prometheus(本身内置了一个数据库>时序数据库)、Victoriametrics(另一个推荐的数据库>时序数据库)。
InfluxDB由InfluxData公司开发,使用Go编程语言编写,适用于存储和检索操作监控、应用指标、物联网传感器数据和实时分析等领域的时间序列数据。它的数据模型基于时间序列,其中时间戳作为索引,不支持对过去数据的修改,因此特别适合写多读少、无事务要求、海量高并发持续写入、基于时间区间聚合分析和基于时间区间快速查询的场景。InfluxDB的主要特色和功能包括:
- 高性能写入:具备秒级写入百万级时序数据的性能。
- 高压缩比低成本存储:提供高压缩比,降低存储成本。
- 预降采样和多维聚合计算:支持预降采样和多维聚合计算,提高查询效率。
- 可视化查询结果:提供可视化查询结果,便于数据分析。
- FLUX查询语言:自1.7和2.0版本以来,引入了FLUX查询语言,这是一种符合时序数据特性的查询语言,支持函数与管道符,提供更强大的查询能力。
- 集群支持:虽然InfluxDB的开源版本仅提供单节点版,但有开源项目提供了基于旧版本的集群方案和反向代理功能,以扩展服务能力。
InfluxDB_33">2、由InfluxDB参与的常见技术方案
InfluxDB_34">2.1、Telegraf + InfluxDB
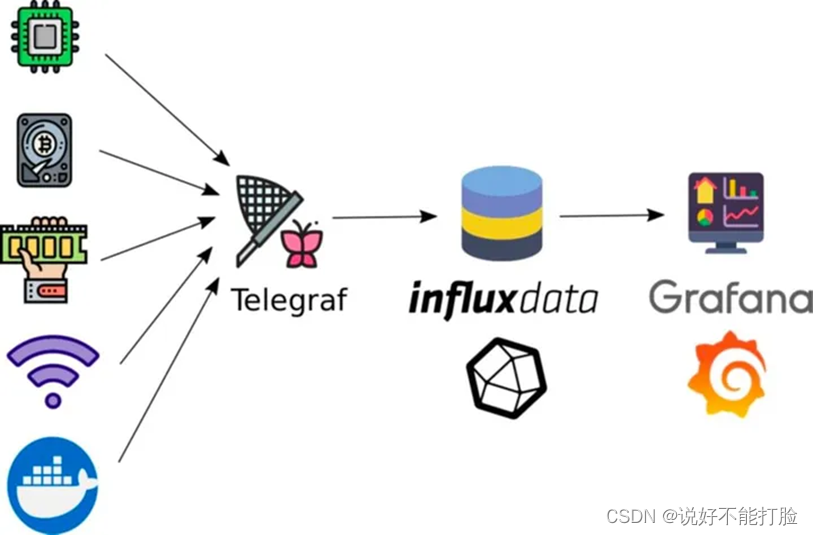
Telegraf是一个基于插件的开源指标采集工具,用于收集和发送来自数据库、系统和物联网传感器的,包括不限于指标、事件的数据。
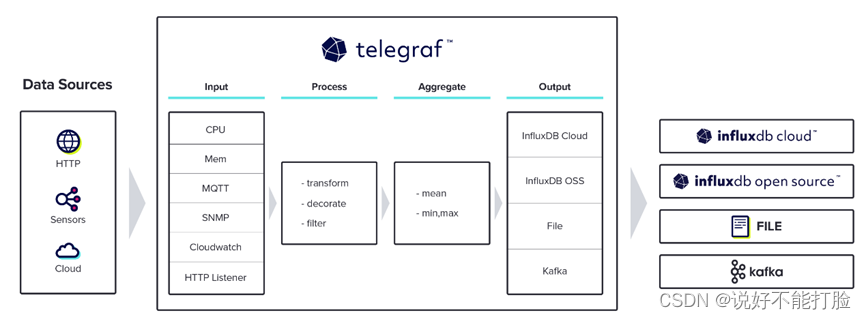
(此图来源于网络)
Telegraf从有四种基本插件类型:Input、processor、aggregator 和 Output 。其中功能如下:
- Input:Telegraf 输入插件从系统、服务和第三方 API 收集指标。
- Processor:处理器插件在发送指标之前转换、修饰和过滤指标,允许收集的数据在数据到达时进行清理。
- Aggregator:聚合器插件创建聚合指标,例如收集和处理的指标的平均值、最小值和最大值。
- Output:输出插件写入各种数据存储、服务和消息队列,如 InfluxDB、Graphite、OpenTSDB、Datadog、Kafka、MQTT、NSQ 等。
Telegraf只是一个指标采集工具(注意,是指标采集而不是日志采集),所以Telegraf采集到的数据是需要进行存储的,这个常选用的数据存储服务就是InfluxDB。
InfluxDB_48">2.2、Prometheus + InfluxDB
Prometheus是一款业界流行的、开源的服务监控系统,Prometheus本身自带一个数据库>时序数据库来存储采集到的数据。
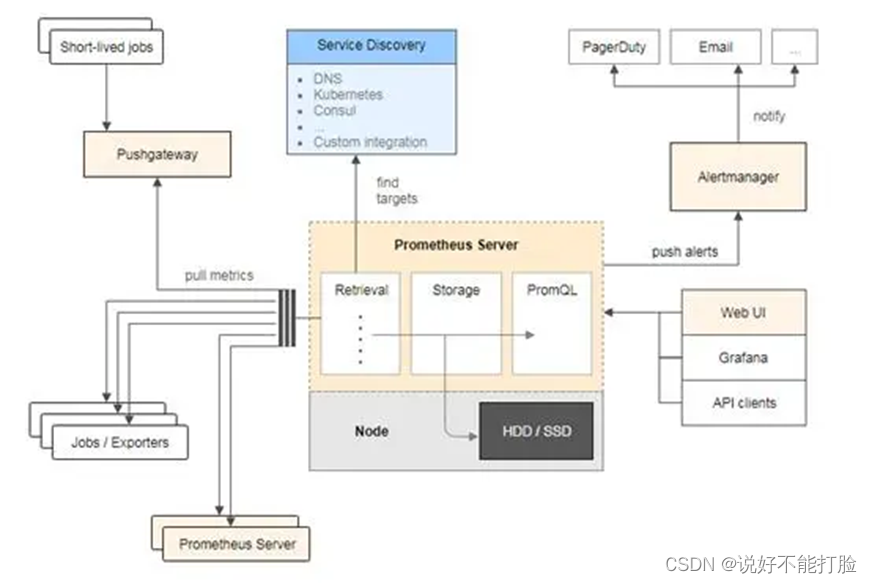
(此图来源于网络)
Prometheus常用的组件如下所示:
-
Prometheus Server:这是Prometheus的核心组件,负责定时从被监控组件中获取数据,并将其存储到时间序列数据库中。Prometheus Server本身就是一个数据库>时序数据库,并且可以替换集成其它多种数据库>时序数据库。它还支持多种服务发现机制,如文件、DNS、Consul、Kubernetes等,可以动态地管理监控目标。此外,Prometheus Server内置了一个Web UI(不是Grafana),通过这个UI可以直接通过PromQL实现数据的查询以及可视化。
-
Exporters:Exporters是一组工具,用于将那些本身不支持直接暴露监控指标的应用程序或服务的指标数据转换为Prometheus可以抓取的格式。例如,Node Exporter用于收集机器级别的指标(如CPU、内存、磁盘使用情况等),而MySQL Exporter则用于收集MySQL数据库的指标数据。其他常见的Exporter还包括Blackbox Exporter(用于网络探测)、Process Exporter(用于监控进程状态)等。
-
Client Libraries:Client Libraries提供了在应用程序中实现自定义指标的方式。这些库支持多种编程语言(如Go、Java、Python等),使得开发者可以轻松地在自己的应用中添加和暴露自定义的Prometheus指标。
-
Pushgateway:Pushgateway是指用于支持短期临时或批量计划任务工作的数据汇聚节点。主要用于短期的Job,此类Job存在的时间较短,可能在Prometheus来pull之前就自行消失了。
在一些特定场景下,使用者可能需要替换Prometheus本身自带的数据库>时序数据库(例如有设施利旧的要求),那么Prometheus也支持第三方数据库>时序数据库。例如可以替换成VictoriaMetrics这款数据库>时序数据库,也可以替换成InfluxDB这款数据库>时序数据库。
InfluxDB__Grafana_65">2.3、InfluxDB + Grafana
Grafana是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。它支持多种数据源,包括 Graphite、InfluxDB、OpenTSDB、Prometheus、Elasticsearch、CloudWatch 和 KairosDB 等,使得用户能够轻松地整合和展示来自不同来源的数据。以上描述是,InfluxDB作为Grafana的一种可以支撑的数据来源。Grafana 的特点包括:
- 快速灵活的客户端图表和面板插件,支持多种可视化指标和日志的展示方式,如热图、折线图等。
- 支持多种数据源,允许用户在同一个图表中混合使用不同的数据源,甚至自定义数据源。
- 提供报警功能,用户可以可视化地为最重要的指标定义警报规则,Grafana 将持续评估它们,并在数据达到阈值时发送通知。
- 支持动态仪表盘和模板变量,使用户能够创建动态和可重用的仪表板。
- 过滤器功能允许用户动态创建新的键/值过滤器,这些过滤器将自动应用于使用该数据源的所有查询。
- Grafana 还支持混合展示、注释和过滤器等功能,进一步增强了其数据可视化和监控能力。
此外,Grafana 提供了开源版(GrafanaOSS)、企业版(Grafana Enterprise)和云版(Grafana Cloud),满足不同用户的需求。截止到本小节介绍的内容,本文都是两个组件、两个组件来介绍它们和InfluxDB之间的配合使用。但实际应用时,肯定是多个组件来进行组合使用,例如 Telegraf + InfluxDB + Grafana,或者 Prometheus + InfluxDB + Grafana。
(此图来源于网络)
InfluxDB_80">2.4、数据日志 + Logstash + InfluxDB
一些业务场景下,我们需要将存储在关系型数据库中的业务数据转存到InfluxDB中,以便利用InfluxDB的工作特点,对这些业务数据建立诸如溯源跟踪、实时状态监控的功能场景。例如建立带有条码物品的真伪鉴别和流转溯源功能,建立车辆物流流转过程的查询功能。
为了减少应用程序开发工作量、降低技术团队的运维难度,类似这样的数据同步不建议编写冗余的代码和脚本进行,而建议采用源数据同步的方式进行。如下图所示:

这样的业务需求场景我们一般采用Logstash采集业务数据,并转换成InfluxDB特定的数据格式完成数据同步。当需要进行查询时,再从InfluxDB中查询数据。
3、基本安装过程
InfluxDB_88">3.1、InfluxDB数据库>时序数据库安装
这里我们选择InfluxDB 2.7.6版本作为安装演示的版本,读者可以在以下路径下载到相关的安装包:
- Window环境安装包的下载(只建议在开发/试用场景下使用,不建议正式环境使用):
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.7.6-windows.zip -UseBasicParsing -OutFile influxdb2-2.7.6-windows.zip
Expand-Archive .\influxdb2-2.7.6-windows.zip -DestinationPath 'C:\Program Files\InfluxData\influxdb\'
以上下载命令中,下载路径是InfluxDB 2.7.6版本,如果读者需要下载其它版本请进行相应更改。另外需要注意的是本次存储路径,以上代码中指定的本地路径是“C:\Program Files\InfluxData\influxdb\”。如果读者需要变化存储路径,也可以进行相应修改。
- Linux(CentOS)设置方式:
# influxdata-archive_compat.key GPG fingerprint:
# 9D53 9D90 D332 8DC7 D6C8 D3B9 D8FF 8E1F 7DF8 B07E
cat <<EOF | sudo tee /etc/yum.repos.d/influxdata.repo
[influxdata]
name = InfluxData Repository - Stable
baseurl = https://repos.influxdata.com/stable/\$basearch/main
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdata-archive_compat.key
EOF
sudo yum install influxdb2
可以看到以上介绍的Linux(CentOS)下的安装方式并不是下载一个安装包,而是增加一个yum仓库,然后使用yum命令进行安装。安装完成后,CentOS会建立一个名叫“influxdb”的服务,请记得将该服务改为自动启动:
systemctl enable influxdb
influxdb服务的配置文件默认被放置在“/etc/influxdb/config.toml”这个位置。注意,我们示例中介绍的是2.7.6版本,和之前的版本不同,其配置文件不再是“influxdb.conf”,而是“config.toml”。例如,要进行默认端口的修改,可以在config.toml配置文件中增加如下配置即可:
http-bind-address = ":80XX"
InfluxDB启动成功后,安装者就可以通过浏览器登录到InfluxDB的管理控制台,并按照控制台的指引建立相关的用户、密码、组织、默认Bucket(桶)等信息。这些界面化步骤相对很简单,本文就不再花费篇幅介绍了。
另外需要注意,以上介绍的都是单节点的安装。如果读者需要进行集群安装,需要购买和下载InfluxDB的企业版本。进行集群设置时,除了按照以上方式设定每个节点外,只需要在每个节点的config.toml配置文件中增加集群节点的说明,包括节点的通讯端口和节点IP。
InfluxDB__132">3.3、InfluxDB 基本概念讲解
在开始InfluxDB的正式使用前,我们需要了解一些InfluxDB中的重要概念。有了这些概念后,我们再在使用过程中,完善对InfluxDB工作原理的理解。
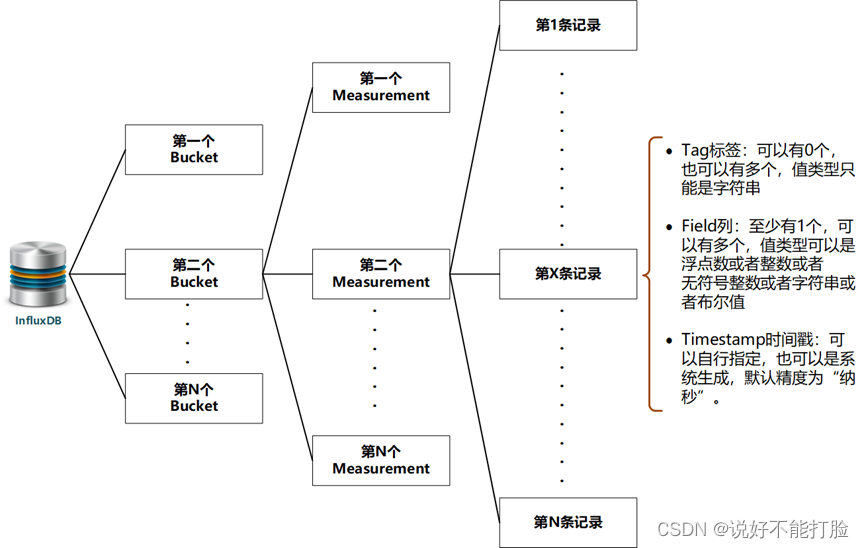
-
Bucket(桶):InfluxDB中的数据都是分桶进行存储的,可以对应关系型数据库中Database的概念或者Schema的概念。实际上就是存放InfluxDB中,多个Measurement(度量/测量)的容器。
-
Measurement(度量/测量):可以对应关系型数据库中的Table(表)的概念,时序化的数据就存储在各个Measurement中。Measurement的名字大小写敏感,且不能使用“_”开头。
-
Tag(标签):一个Measurement中可以指定多个Tag,每个Tag可以对应关系型数据库中的Index(索引)概念。不同的是Measurement中的每个Tag都有实际数据,而不用依据某个具体的Field(列)进行设定。标签信息在Measurement中并不是必须的。
-
Field(列):一个Measurement中可以指定多个Field(列)。InfluxDB中的Filed(列)概念,也相当于关系型数据库中的Field(列)概念。一个Measurement中至少需要一个Field,且Field的名字大小写敏感,其数据值的类型可以是:浮点数、整数、无符号整数、字符串和布尔值。
-
Timestamp(时间戳):存储在Measurement中的每一条数据都会有一个时间戳,这个时间戳可以是数据添加时,由操作者指定;也可以是数据添加时,利用应用程序当前的时间自动生成。InfluxDB支持最少“纳秒”级单位的时间戳。
InfluxDB_146">4、使用Java操作InfluxDB
4.1、多种连接方式
InfluxDB提供了多种编程语言的Client功能,诸如Golang、Python、PHP等主流语言,这里我们主要介绍Java-Client。InfluxDB为Java提供了三种数据写入的调用方式,它们是原生数据格式的调用、对象化调用和注解调用;另外InfluxDB还为Java提供了两种数据查询的调用方式,它们是脚本化的查询方式和基于InfluxQL的查询方式。
要使用InfluxDB-Java的客户端功能,首先需要为你的Java程序引入对应的功能包,以下是使用Maven的引用方式:
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>6.6.0</version>
</dependency>
4.1.1、使用数据串格式进行数据添加
InfluxDB本身具备一种独特的数据描述格式,见下图:

以上数据串格式中的各个要素,已经在上文介绍过了,这里就不再进行赘述。各种应用程序的InfluxDB-Client都可以通过这种原生的数据串格式进行数据的添加操作。以下是InfluxDB-Java-Client的相关示例代码:
// ......
// 以下设置信息后文不再赘述
String token = "这是当时InfluxDB安装初始化时,系统生成的一个token";
String bucket = "这是你influxDB中的bucket信息";
String org = "这是当时InfluxDB安装初始化时,设定的组织信息";
InfluxDBClient client = InfluxDBClientFactory.create("http://localhost:8086", token.toCharArray());
// 通过数据串进行添加
List<String> records = Lists.newArrayList();
records.add("cputable2,tag1=\"192.168.100.1\" field4=0.40,field1=110 ");
records.add("cputable2,tag1=\"192.168.100.2\" field4=0.23,field1=64 ");
WriteApiBlocking writeApi = client.getWriteApiBlocking();
// 注意这里要求设定的时间精度为毫秒,默认为纳秒
writeApi.writeRecords(bucket, org, WritePrecision.MS, records);
// ......
以上代码中,我们向cputable2这张“数据表”添加两条(多条)记录。这些记录有一个“索引”,命名为tag1,并且有两个字段,分别是field1、field4,这两个字段的类型分别是浮点型和整型。
4.1.2、使用Point “数据点” 对象进行数据添加
InfluxDB-Java-Client还向技术人员提供了一个Point对象进行数据添加,这种添加方式相比于上一种添加方式更便于技术人员理解。以下是相关示例代码:
// 创建一个Point实例
// lastTime变量是一个时间对象
Point point = Point.measurement("cputable2")
.addTag("tag1", "192.168.100.3")
.addField("field1", 99d)
.addField("field4", currentFloat)
.time(lastTime.toInstant(), WritePrecision.NS);
WriteApiBlocking writeApi = client.getWriteApiBlocking();
writeApi.writePoint(bucket, org, point);
以上代码中,我们向cputable2这种“数据表”添加一条记录。这条记录有一个“索引”,命名为tag1,并且有两个字段分别是field1、field4,这两个字段的类型分别是整型和浮点型。另外注意,这里的时间戳是由开发人员指定的一个时间,时间精度为纳秒。
4.1.3、使用对象进行数据添加
InfluxDB-Java-Client还向技术人员提供了一种基于注解+自定义对象的数据添加方式。这种添加方式最接近Java开发者的编程习惯。以下是相关示例代码:
// 首先创建一个名为Men的业务模型
@Measurement(name = "mem")
public static class Mem {
@Column(tag = true)
String host;
@Column
Double used_percent;
@Column(timestamp = true)
Instant time;
}
// 然后开始API调用
Mem mem = new Mem();
mem.host = "host1";
mem.used_percent = 23.43234543;
mem.time = Instant.now();
WriteApiBlocking writeApi = client.getWriteApiBlocking();
writeApi.writeMeasurement(bucket, org, WritePrecision.NS, mem);
以上代码摘自于InfluxDB自带的示例文档,在代码中我们首先定义了一个模型Men,并在模型上使用@Measurement注解。这个注解表示该模型是一个匹配InfluxDB数据库某个测量/度量的模型。模型中通过@Column(tag = true)注解定义了一个“索引”,名叫host,通过@Column(timestamp = true)注解,定义了模型中的time属性是“数据表”中匹配的时间戳信息,最后模型中的used_percent属性是“数据表”中的一般字段,字段类型为浮点型。
4.1.4、使用查询脚本进行数据查询
写入到InfluxDB的数据,可以通过两种方式进行查询。这里先介绍第一种,就是通过InfluxDB提供的查询脚本进行查询。以下是相关示例代码:
// ......
QueryApi queryApi = client.getQueryApi();
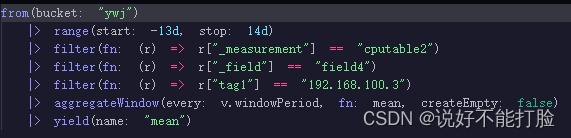
String queryValue = "from(bucket: \"ywj\") |> range(start: -7d , stop: 12h) "
+ " |> filter(fn: (r) => r[\"_measurement\"] == \"cputable2\") "
+ " |> filter(fn: (r) => r[\"_field\"] == \"field4\") "
+ " |> filter(fn: (r) => r[\"tag1\"] == \"192.168.100.3\")";
List<FluxTable> results = queryApi.query(queryValue, org);
// ......
以上代码中,我们通过from脚本命令指定了本次查询针对的“数据库”名为ywj,使用range脚本命令指定查询数据的时间戳范围为当前时间之前7天到当前时间之后12小时;多次使用filter脚本命令,指定查询的“数据表”为“cputable2”、查询的字段只包括field4这个字段、查询的标签(tag1)值只能是“192.168.100.3”。通过InfluxDB提供的官方文档【点击查看】,可以了解更多的脚本命令。
以下再给出一段查询脚本示例,这段示例的效果可以通过InfluxDB自带的管理控制台查看到相关效果:
4.1.5、使用InfluxQL进行数据查询
InfluxQL是一种查询语言,和SQL相比而言,其SQL 95标准中的语法并不是全部兼容。以下是一条InfluxQL查询语句。
SELECT field4 FROM cputable2 WHERE time < now() + 12h AND time > now() - 7d
以上语句中,Measurement可以看做表名放置在查询语句的FROM部分,需要查询的字段放置在SELECT部分。有意思的WHERE条件部分,在这个名叫cputable2的度量中,并没有一个叫做time的Field字段。查询语句中的time代表的是时间戳,这里的查询条件是时间戳的值满足以当前时间之前7天到当前时间之后12个小时的一个时间段。这里本文再给出相关示例代码:
// ......
// 通过InfluxQL进行数据查询(类似SQL)
// 可参考:https://www.cnblogs.com/zjdxr-up/p/17527569.html
InfluxQLQueryApi qLQueryApi = client.getInfluxQLQueryApi();
String influxQL = "SELECT field4 FROM cputable2 WHERE time < now() + 12h AND time > now() - 7d";
InfluxQLQuery influxQlQuery = new InfluxQLQuery(influxQL, "ywj");
InfluxQLQueryResult queryResult = qLQueryApi.query(influxQlQuery);
List<Result> qlResults = queryResult.getResults();
// ......
// 以下进行输出
for (Result result : qlResults) {
List<Series> series = result.getSeries();
for (Series serieItem : series) {
List<Record> records = serieItem.getValues();
for (Record record : records) {
Object timeObject = record.getValueByKey("time");
Object field4Object = record.getValueByKey("field4");
System.out.println("record : timeObject = " + timeObject + " | field4Object = " + field4Object);
}
}
}
这里我们主要介绍一下输出结果,以上代码的输出结果类似如下:
......
record : timeObject = 1718923686000000000 | field4Object = 8.489629745483398
record : timeObject = 1718924400000000000 | field4Object = 0.88
......
record : timeObject = 1718929200000000000 | field4Object = 1.11
record : timeObject = 1718935729402000000 | field4Object = 0.21
......
record : timeObject = 1718937328259000000 | field4Object = 0.95
record : timeObject = 1718938026430000000 | field4Object = 1.95
......
record : timeObject = 1718949629692000000 | field4Object = 2.88
record : timeObject = 1718953400000000000 | field4Object = 8.830526351928711
......
由此可见查询结果输出时,可以输出多个series,每个series中携带的values才是查询结果。可以通过每条结果(每个结果对应一个Record对象)的getValueByKey()方法,可以拿到具体某一个字段的值。InfluxQL查询语言的更多具体讲解,可参考InfluxDB提供的官方文档【点击查询】。
4.2、常见问题汇总
-
InfluxDB-Java-Client的Client对象在使用完成后需要进行关闭,也就是调用close()方法进行关闭。
-
字段类型需要保持一致:如果FieldX字段进行第一次数据添加时,指定FieldX字段类型为“浮点型”;但是后续添加数据时,指定FieldX字段类型为“字符串”,这时添加操作将会报错。
-
InfluxDB使用的时间戳基于Unix Timestamp,也就是从1970-01-01 00:00:00时间开始经过的时间。精度为纳秒或者精度为毫秒时,时间戳的值是不一样的,技术人员指定时需要关注这个问题。
-
InfluxDB CLI是一个InfluxDB的客户端,这个客户端可以通过命令的方式对InfluxDB进行操作。在InfluxDB官方文档中有相关的安装、使用说明,读者可以自行进行阅读。