最近在回顾《西瓜书》的理论知识,回顾到最后一章——“强化学习”时对于值函数部分有些懵了,所以重新在网上查了一下,发现之前理解的,包括网上的大多数对于值函数的描述都过于学术化、公式化,不太能直观的理解值函数以及值函数的推导,我琢磨了一下,所以这篇文章想通过流程图的形式跟大家分享一下我个人对值函数的思考,如果有误,请见谅。当然,如果这篇文章还能入得了各位“看官”的法眼,麻烦点赞、关注、收藏,支持一下!
一、概念简述
状态值函数V(s):表示智能体从当前状态s出发,按照指定策略π执行直至终止的累积奖励
动作值函数Q(s,a):表示智能体从当前状态s出发,执行指定动作a后,再按照指定策略π执行直至终止的积累奖励
PS:建议小伙伴们去看一下我之前写的文章——《机器学习——强化学习中的“策略π”的个人思考》,这样可能更好的帮助大家理解“指定策略”这一概念
二、值函数详解及推导
为方便大家直观的了解值函数的相关概念,我先从最特殊的情况跟大家进行讲解,如下图1所示:

图1
图1中S表示状态,a表示动作,R表示执行某一动作后获得的总奖励,r表示执行某一动作所对应的奖励
图1是一种最特殊的情况,即当智能体状态为S0时,必然执行a0动作,执行a0动作后状态必然会改变至S1……其中,必然代表着概率是100%。从图中不难发现最后执行完毕后智能体的状态由S0变到了S4,状态值函数V(S0)=动作值函数(S0,a0),即:
![]()
进一步的,当只能体为状态S0时,其可执行的动作不仅仅是a0时,怎么办?我将结合图2继续说明:
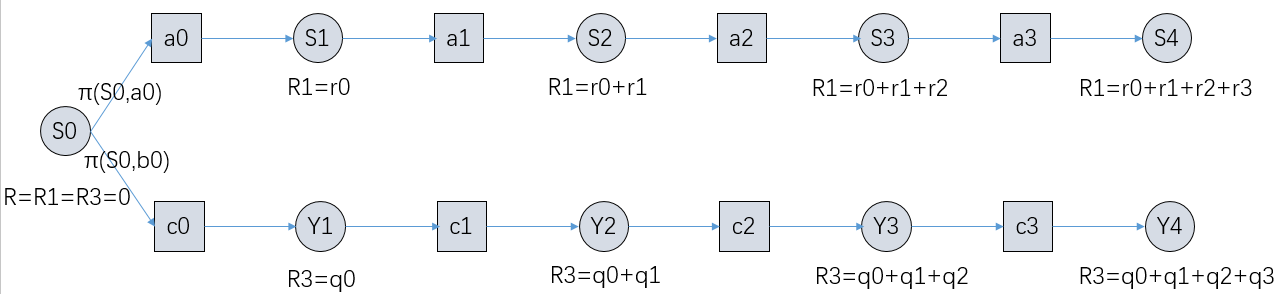
图2
图2中S和Y表示状态,a和c表示动作,R表示执行某一动作后获得的总奖励,r和q表示执行某一动作所对应的奖励,π(S0,a0)表示按照策略π执行时,在当前状态S0选择执行动作a0的概率,π(S0,c0)同理,不做过多解释。
从图2中,可以很直观的看出,状态值函数V(S0)不再等于单一的动作值函数Q(S0,a0)或者Q(S0,c0),而是按照给定的概率由两个状态值函数构成,即如下所示:
![]()
图2中,智能体状态为S0时,可以执行的动作有两个,观察公式不难发现,此时,状态值函数V=不同的动作值函数Q与执行该动作的概率π的乘积的累加和,因此,我们就可以将一个状态、两个动作推广到一个状态、多个动作,并得到相应的值函数,如下所示:
![]()
符号说明:上式中的s对应图2中的S0,表示当前状态,a对应的是图2中的a0和c0,表示当状态所要执行的动作,π(s,a)表示当前状态s下执行动作a的概率
既然一个状态可执行的动作不唯一,那么一个动作产生的状态是否也是不唯一的呢?我的答案是:是的!!!对此,我们依然采用从特殊到普遍的推导方法,来帮助大家更加直观的理解,直接上图:
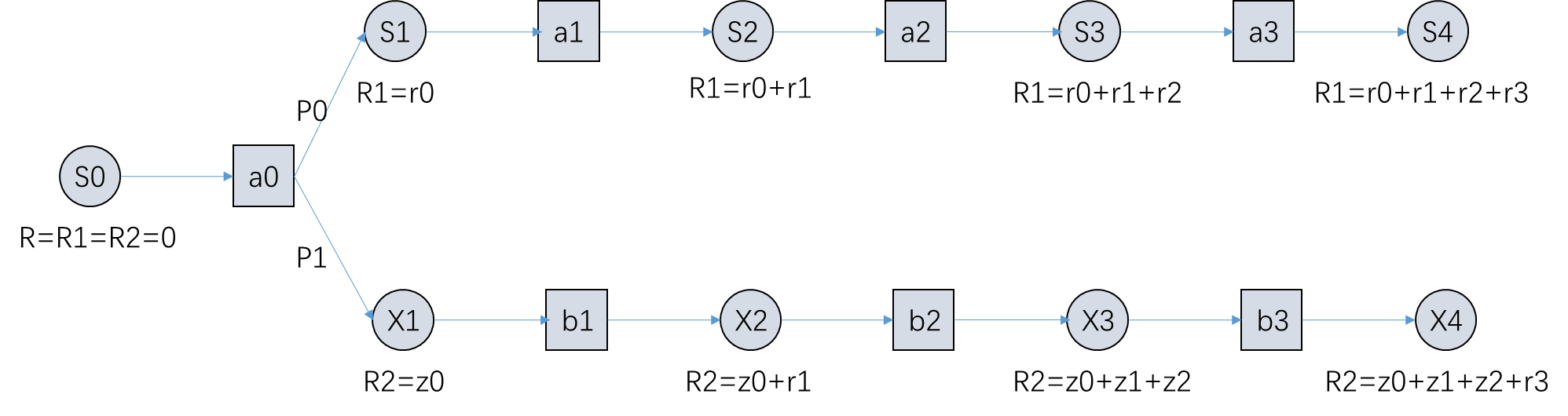
图3
图3中S和X表示智能体状态,a和b表示动作,R表示执行某一动作后获得的总奖励,r和z表示执行某一动作所对应的奖励,P0表示智能体在状态S0时执行动作a0后状态变为S1的概率,P1同理,不做过多解释。
从图3中,可以很直观的得到如下几条等式:
![]()
![]()
![]()
![]()
因此,通过观察上述的公式,我们就可以将一个动作、两个状态推广到一个动作、多个状态,并得到相应的动作值函数,如下所示:
![]()
符号说明:上式中的s对应图3中的S0,表示当前状态,a对应的是图3中的a0,表示当状态所要执行的动作,s'对应图3中的S1和X1,表示下一个状态,P对应图3中的P0和P1,表示执行当前动作后状态变化的概率,Rs对应图3中的r0和z0,表示执行动作a且当前状态由s变到s'时环境返回的奖励,V(s')对应图3中的V(S1)和V(X1),表示智能体从下一状态s'出发,按照指定策略π执行直至终止的累积奖励,π(s,a)表示当前状态s下执行动作a的概率
上面已经讲了一个状态可能执行多个动作,以及一个动作可能产生多个状态的情况,那么有些脑子非常非常灵活的小伙伴可能已经想到,我们是否可以将两者结合,来推导出一下多个状态,多个动作的情况呢?我的答案是:可以!!!直接上图:
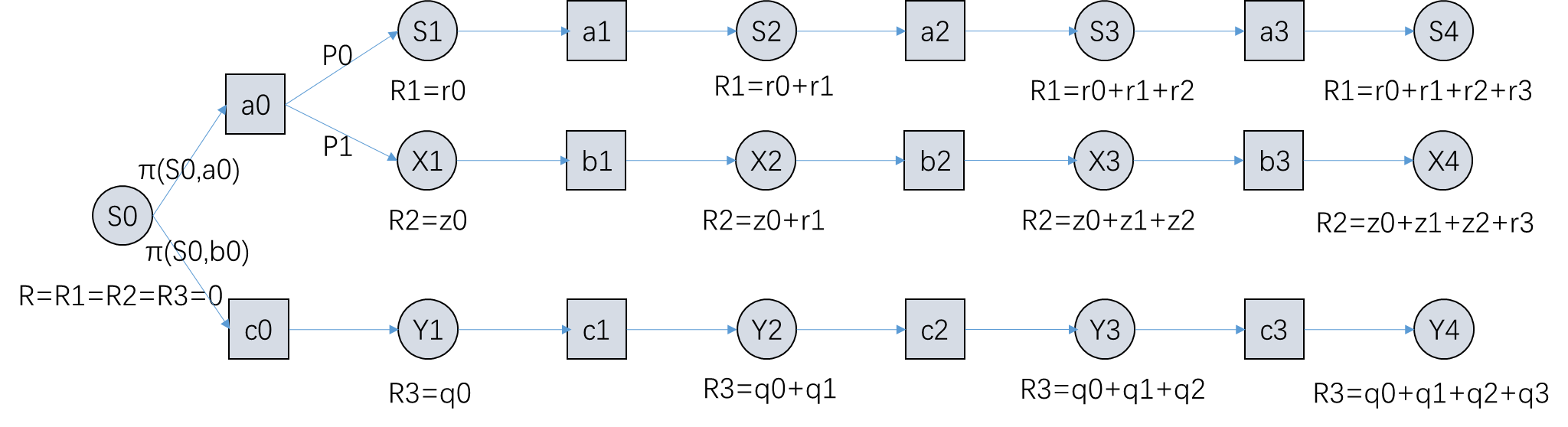
图4
通过对比图2、图3和图4,不难发现,图4是图2和图3的有机结合,图4中既存在一个状态可能执行两个动作,又存在一个动作可能产生两个状态的情况,因此,我们可以从图4中得到如下公式:、
![]()
![]()
![]()
通过观察上述的公式,我们就可以得到多个状态,多个动作下的状态值函数,即如下所示:
![]()
符号说明:上式中的s对应图4中的S0,表示当前状态,a对应的是图4中的a0和c0,表示当状态所要执行的动作,s'对应图4中的S1、X1以及Y1,表示下一个状态,P对应图4中的P0和P1,表示执行当前动作后状态变化的概率,Rs对应图4中的r0、z0以及q0,表示执行动作a且当前状态由s变到s'时环境返回的奖励,V(s')对应图4中的V(S1)、V(X1)以及V(Y1),表示智能体从下一状态s'出发,按照指定策略π执行直至终止的累积奖励,π(s,a)表示当前状态s下执行动作a的概率
三、T步积奖例累函数推导说明
一些细心的小伙伴可能发现了,我上面列的一些公式可能跟市面上的大部分参考书不一样,但是内部的机理是一致的,为了防止有些朋友会存在困惑,所以我解释一下:
1、符号不一样:为了增加区分度,让各位的更清楚,所以自己增设了一些符号
2、奖励函数不一样:很多人在参考书上看到的奖励函数应该都是T步平均奖励,或者γ折扣奖励,而上文以T步的累计和作为奖励,之所以采用T步的累加和作为奖励,是因为这样大家可以更加的直观了解两个值函数之间的关系与转换
为了跟广大的参考书籍保持一致,下面这一小节,我主要对T步积累奖励函数及其相关推导进行说明。
这里给出的T步积累奖励函数的原公式来源于周志华老师的《西瓜书》
先给出《西瓜书》中的公式:
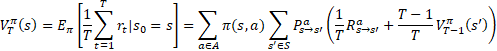
看到《西瓜书》上的公式,我相信大部分小伙伴都发现了,我上文中推导出来的黄色高亮公式与《西瓜书》中的公式非常像,唯一区别就在于《西瓜书》中的公式中多出了![]() 和
和![]() ,为什么会这样呢?
,为什么会这样呢?
其实原因很简单,《西瓜书》中的公式是以T步的平均值作为奖励,而上文中是以T步的累加和作为奖励。
当我们以T步的平均值作为奖励,也就是说,我们可以将每步的奖励看做是原来每步奖励的T分之一,于是图1将转换成下图5:

图5
声明:本文中的 ![]() 和《西瓜书》公式中的
和《西瓜书》公式中的![]() 的表达式是不一致的,查看下面式子中红色标记部分即可知晓
的表达式是不一致的,查看下面式子中红色标记部分即可知晓
于是,图5中的信息可表示为:
![]()
![]()
![]()
![]()
![]()
![]()
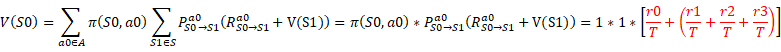
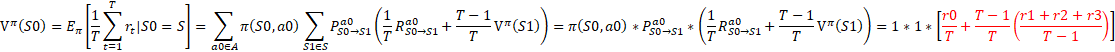
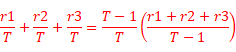
通过对比上面的公式,我们不难发现,其中![]() 中的T主要是因为每步的奖励变为了原来的T分之一,而
中的T主要是因为每步的奖励变为了原来的T分之一,而![]() 主要是为了保证
主要是为了保证![]() 的显示格式统一。
的显示格式统一。
通过上文,我想我应该讲清楚了T步积累奖励函数,如果有小伙伴还有不明白的,欢迎评论,另外,因为本人有点懒,又累了,所以就不对γ折扣奖励函数进行说明,原理跟T步积累奖励函数一致